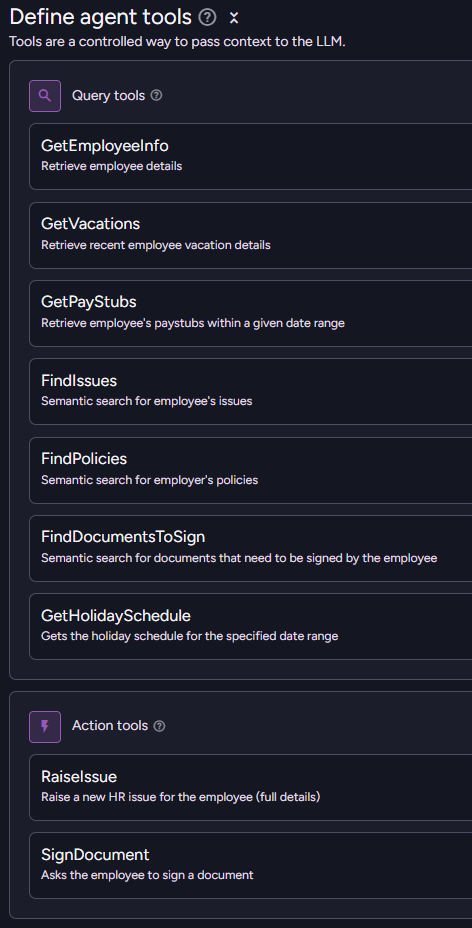
When building AI Agents, one of the challenges you have to deal with is the sheer amount of data that the agent may need to go through. A natural way to deal with that is not to hand the information directly to the model, but rather allow it to query for the information as it sees fit.
For example, in the case of a human resource assistant, we may want to expose the employer’s policies to the agent, so it can answer questions such as “What is the required holiday request time?”.
We can do that easily enough using the following agent-query mechanism:

If the agent needs to answer a question about a policy, it can use this tool to get the policies and find out what the answer is.
That works if you are a mom & pop shop, but what happens if you happen to be a big organization, with policies on everything from requesting time off to bringing your own device to modern slavery prohibition? Calling this tool is going to give all those policies to the model?
That is going to be incredibly expensive, since you have to burn through a lot of tokens that are simply not relevant to the problem at hand.
The next step is not to return all of the policies and filter them. We can do that using vector search and utilize the model’s understanding of the data to help us find exactly what we want.
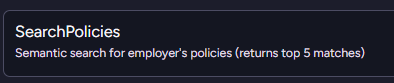
That is much better, but a search for “confidentiality contract” will get you the Non-Disclosure Agreement as well as the processes for hiring a new employee when their current employer isn’t aware they are looking, etc.
That can still be a lot of text to go through. It isn’t as much as everything, but still a pretty heavy weight.
A nice alternative to this is to break it into two separate operations, as you can see below:
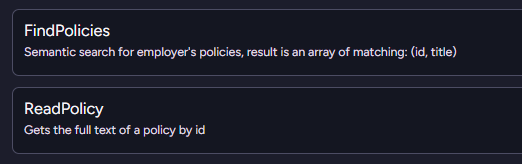
The model will first run the FindPolicies query to get the list of potential policies. It can then decide, based on their titles, which ones it is actually interested in reading the full text of.
You need to perform two tool calls in this case, but it actually ends up being both faster and cheaper in the end.
This is a surprisingly elegant solution, because it matches roughly how people think. No one is going to read a dozen books cover to cover to answer a question. We continuously narrow our scope until we find enough information to answer.
This approach gives your AI model the same capability to narrowly target the information it needs to answer the user’s query efficiently and quickly.